Daniela Vázquez: científica de datos extrae y abre datos del Parlamento Uruguayo
Publicado el Lunes, 9 de abril de 2018Si bien Uruguay ha avanzado bastante en el tema de Datos Abiertos, todavía queda mucho por hacer. El Parlamento en particular no publica Datos Abiertos. Sí publica diarios de sesiones, pero en PDF, una de las pesadillas de los activistas de datos. No pueden ser directamente procesados en código de máquina a diferencia de formatos como CSV, JSON, txt y demás. Tampoco hay una API de dónde obtener los datos, hay que descargarlos desde el sitio web del Parlamento.
Pero esto no impidió que Daniela Vázquez obtuviera y procesara los datos. En su blog escribió "Scrapeando las Sesiones Parlamentarias de Uruguay", donde nos cuenta detalladamente cómo programó un scraper para descargar los archivos PDF usando rvest y extrajo el texto a través de pdftools, herramientas del lenguaje de programación R. ¡Lectura muy recomendable! A pesar de no haber visto nunca nada en R, el post está muy bien explicado y me resultó muy entendible.
Este estudio desencadenó en "¿De qué se habló en el Parlamento uruguayo desde 2017?", donde hace un análisis de los textos levantados en la entrada anterior, y presenta distintos estudios de las sesiones de Diputados y Senadores: Con qué frecuencia se reunieron, Qué tan largas fueron las sesiones, Palabras más comunes y Análisis de sentimiento.
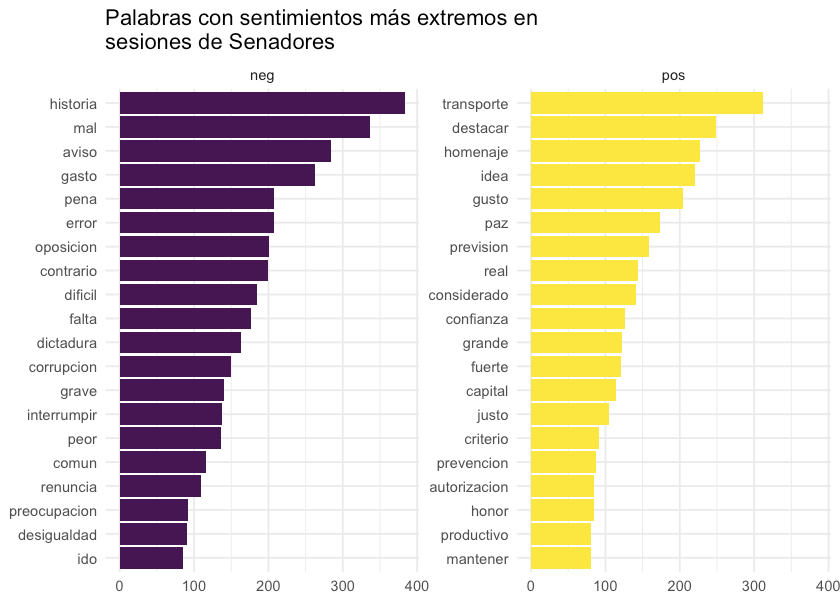
Además de explicar cómo hizo cada estudio, su post está complementado con gráficas como la que ven en la imagen que acompaña este post. La información objetiva y clara, como debe ser para que cada uno la interprete críticamente y saque sus conclusiones.
Como si todo esto fuera poco, Daniela subió el código fuente de su trabajo a GitHub, y comparte los datos en formato CSV para las sesiones de Diputados y Senadores. Muchas gracias Daniela por compartir tu conocimiento y gran trabajo. Que haya cada vez más rebeldes de los datos 💪









No hay comentarios en este post - Feed de comentarios
Dejar un comentario